Technical Debt... GURU LEVEL UNLOCKED!

As Software Engineers we know that Technical Debt and Legacy Code are familiar concepts we have to live with. Code healthiness and maintenance are challenging, so let’s dive into tips and techniques on how to effectively address this problem.
“Technical Debt is the additional effort and work required to complete any software development.”
- Introduction
- The Questions
- Fact: Our Software is Terrible
- What is Legacy Code?
- What is Reckless Debt?
- What is Technical Debt?
- Real case scenario: Adding a new feature
- ROOKIE Level Unlocked! Static Code Analysis
- EXPERIENCED Level Unlocked! Tech Debt Radar
- GURU Level Unlocked! Behavioral Code Analysis
- Covering more Social Analysis
- Extra Ball
- Paying Technical Debt
- Wrapping up
- Congratulations! Technical Debt GURU Level Unlocked!
- Books for reference
- Further reading
Introduction
This is a long article that I wanted to squeeze in a smaller one but it was almost mission impossible to get rid of some important/valuable information. I hope you enjoy and find it helpful.
Feel free to provide feedback, which as usual, is more than welcome.
With that being said, I would like to start with a quote from Robert C. Martin:
“Bad code is always imprudent”
I cannot agree more with this, and no matter what I sell you in this post :), there is NEVER a good reason to write bad code.
The Questions
We as Engineers, Tech Leads and Managers know that technical debt is one of our worst enemies when it comes to codebases and software projects in general It can be very frustrating and demotivating thus making our life a bit more complicated…But…
- What is technical debt really?
- And Legacy code?
- Is there a proportional relationship between them?
- How can we measure and determine the healthiness of our project?
- And once we measure it, how can we finally address the problem?
Let’s try to answer these questions and also explore in depth different techniques and strategies that will help us effectively deal with it.
Fact: Our Software is Terrible
In an ideal world, a project would be:
- Finished on time.
- With a clean code design.
- Additional features.
- Tested twice.
- On Budget.
If that is your reality, then you can stop reading this post, luckily you have UNLOCKED the LEVEL SUPERHEROE, so please share your thoughts and ideas, I am more than curious to know how you have achieved it.
Otherwise, welcome to my world, where we create authentic monsters: giant beasts full of technical debt, legacy code, issues and bugs.
And if you let me add more, that also includes coordination and communication problems across the entire organization. Yes! Our Software is terrible and we know it is TRUE, which does not make it any special, right?
What is Legacy Code?
There are many definitions of legacy code and some of them, in my opinion, contradict themselves, so since you are familiar with the concept, let’s keep it simple:
“Legacy code is code without tests.”
Testing nowadays should be implicit in our engineering process when writing code. So if you are not at least unit testing your codebase, run and do it, it is a command :).
What is Reckless Debt?
I came across this term lately and it looks like we can use it as a synonym of technical debt, but in reality, here is the formal definition:
“Reckless Debt is code that violates design principles and good practices.”
That means that all code generated by us and our team is junk (not done on purpose of course).
Moreover, Reckless Debt will lead to Technical Debt in the short/mid term and it is also a signal that your team needs more training, or you have too many inexperienced or junior developers.
What is Technical Debt?
Here I will rely on Martin Fowler:
“Technical Debt is a metaphor developed by Ward Cunningham to help us think about this problem. Like a financial debt, technical debt incurs interest payments, which come in the form of the extra effort that we have to do in future development because of the quick and dirty design choice. We can choose to continue paying the interest, or we can pay down the principal by refactoring the quick and dirty design into the better design.”
Real case scenario: Adding a new feature
So let’s put our day to day life back into our heads. In this case we have decided to add a new functionality to our project, so here we have 2 well defined options:
The “easy” way, built up with messy design and code, which will get us there way faster: REMEMBER WE NEED TO PAY THE INTEREST.
The “hard” way, built up with cleaner code and a meaningful and consistent architecture. Without a doubt this will take more time but it is going to be more EFFICIENT IN TERMS OF INTEREST COST.
“Accept some short term Technical Debt for tactical reason.”
It is not uncommon that at some point we need to develop something quickly because of time to market (or market experiment), or perhaps there is a new internal component that needs to be shipped in order to be used across the entire organization and we are contributing to it (a module for example), and we code it fast with not the best design until we can come up with a more robust and effective solution.
“No matter what is the reason, but part of this decision to accept technical debt is to also accept the need to pay it down at some point in the future. Having good regression testing assets in place, assures that refactoring accepted technical debt in the future, can be done with low risk.”
Let’s move on and see how we can analyze and inspect our codebase in order to detect technical debt.
ROOKIE Level Unlocked! Static Code Analysis
It is the most basic and fundamental building block when it comes to measuring technical debt at a code level.
Most of us are familiar with this practice since it aims to highlight potential bugs, vulnerabilities and complexity.
But first, in order to interpret the results of static code analysis and quantify technical debt, we need to be familiar with a bunch of code metrics:
Cyclomatic Complexity: stands for the complexity of classes and methods by analyzing the number of functional paths in the code (if clauses for example).
Code coverage: A lack of unit tests is a source of technical debt. This is the amount of code covered by unit tests (we should take this one responsibly, since testing getters and setter can also increase code coverage).
SQALE-rating: Broad evaluation of software quality. The scale goes from A to E, with A being the highest quality.
Number of rules: Number of rules violated from a given set of coding conventions.
Bug count: As technical debt increases, the quality of the software decreases. The number of bugs will likely grow (We can complement this one with information coming from our bug tracker).
There is a variety of tools out there (free for open source projects), which provide the above information out of the box, and most of the time, they can be easily integrated either with your CI infrastructure or directly with our version control system tools like github/gitlab/git.
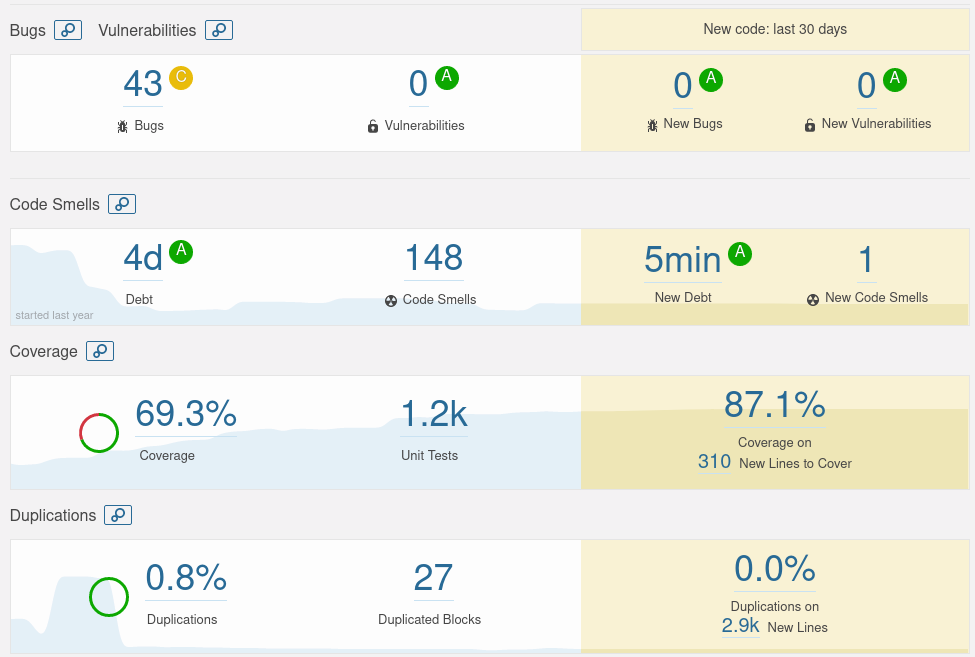
Here is a screenshot of one codebase example using the online open source tool SonarQube:
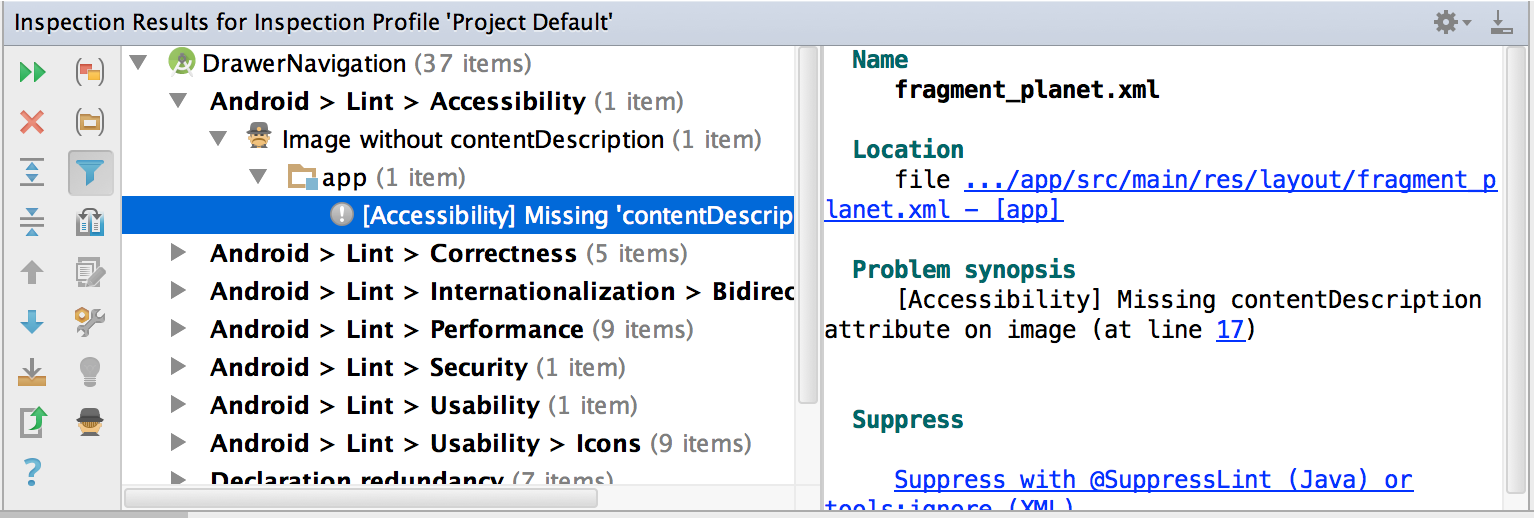
Lint is also a very flexible and popular one (there are plugins for the most popular IDEs and you can write your own custom rules, in this case on Android):
Static code analysis should be our first mandatory step to tackle and measure technical debt.
So let’s make sure we include as a regular practice in our engineering process.
EXPERIENCED Level Unlocked! Tech Debt Radar
A Tech Debt Radar is a very simple tool that has personally given me really good results (while working at @SoundCloud, within the android team, it was (and it is AFAIK) a regular practice).
“We should know that this is not an automated tool (like the ones mentioned above) and I define it as a Social Technical Debt Detector by Experience”.
The idea is pretty simple: all the feedback related to how difficult is to work with the current codebase, comes from actually the developers working with it (by experience).
You can see a Tech Debt Radar in the picture below:
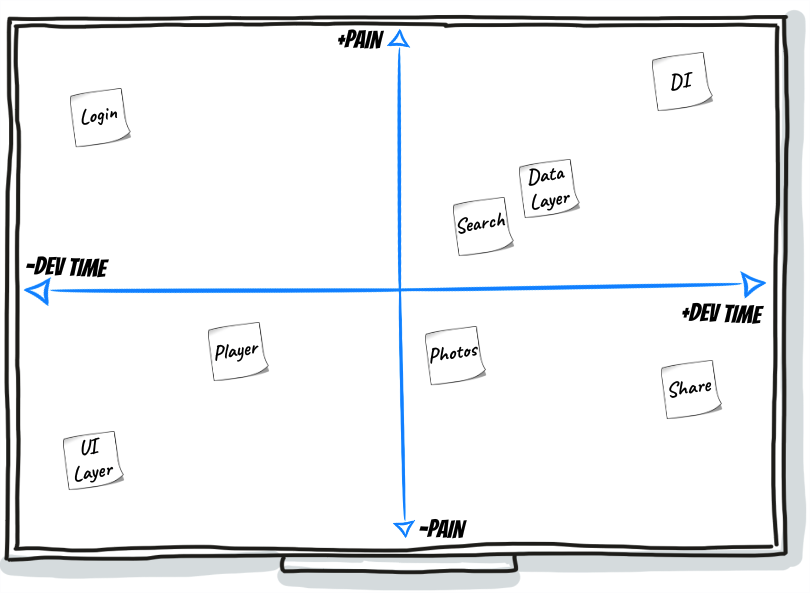
As we can see, there is a board with a few post-its representing each one either a feature or even an area of the codebase which eventually is hard to work with.
Then we have 2 axys:
- X: represents the level of pain when working with a specific part of the codebase.
- Y: represents how much development time would it take to improve the mentioned piece of code.
At a process level, this is done in a meeting with the development team and a technical debt captain (someone who will be in charge of analysing technical debt).
Basically each member of the team, will have the chance to place these post-its depending on how much pain (X axis) each is causing, and how much development time (Y axis) is required to fix it.
This would be mostly common sense (with strong arguments and an explanation of the whys) in the beginning but I can ensure that it will get better over time with the accumulated experience.
As an example on the board, let’s look at the DI card (Dependency Injection). It looks like it is a very painful area in our project and refactoring it will require a big effort. On the other hand, Login is causing a lot of pain and fixing it will not be very complicated.
With this in mind you can get some conclusions:
By addressing all features that are painful and at the same time require little development time (the ones placed upper left corner), we will be able to provide a lot of value and improvement by fixing them.
The rest of the functionalities will require some workout to be prioritized and refactored. As a rule of thumb, discuss with the team and use a divide and conquer approach (split up big problem into smaller ones).
Once we gather all this information, we need to keep track of all the collected feedback, so feel free to use your favorite tool for that purpose.
Even a document might do the job: this is a matter of taste, as soon as you have a place to store all this data and see the evolution over time.
A Technical Debt Radar will not provide the level of granularity and details that any other automated tool out there might do, but it is totally worth a try, and a very valuable method that perfectly complements our codebase analysis with the purpose of understanding the most painful spots, and the most important, is that this information comes from us, from the feedback of the people who daily work with the code.
Remember to have these meetings regularly (minimum once every 2-3 weeks) in order to keep an eye on how much progress (positive or negative) has been done.
GURU Level Unlocked! Behavioral Code Analysis
It is obvious that technical debt have a 1 to 1 relationship with legacy code but there is another important factor to take into consideration: the social part of our organization, which basically emphasizes in how we as human beings interact with each other (as a team), with customers, with the rest of the organization and with the code itself.
All this comes from the fact, that over the years there has seen changes in the way we work and interact with each other, which led to modifications in collaboration techniques, tools and again, the code itself.
References like Adam Tornhill in the area of human psychology and code are helping us to understand a bit more this social part.
Before continuing, let’s recap what a traditional static code analysis tool can do for us:
- …focus on a snapshot of the code as it looks right now.
- …find code that is overly complex.
- …find code which has heavy dependencies on other parts.
In conclusion, static analysis is a very useful tool and as pointed out above, should be our first step when it comes to code inspection, but there is an important gap to fill in:
“Static analysis will never be able to tell you if that excess code complexity actually matters – just because a piece of code is complex doesn’t mean it is a problem.”
Social aspects of software development like coordination, communication, and motivation issues increase in importance and all these softer aspects of software development are invisible in our code:
“Adam Thornill: if you pick up a piece of code from your system there’s no way of telling if it has been written by a single developer or if that code is a coordination bottleneck for five development teams. That is, we miss an important piece of information: the people side of code.”
Behavioral code analysis emphasizes trends in the development of our codebase by mining version-control data.
Since version-control data is also social data, we know exactly which programmer that wrote each piece of code and with this in mind, it is possible to build up knowledge maps of a codebase, for example, like the one in the next figure which shows the main developers behind each module:
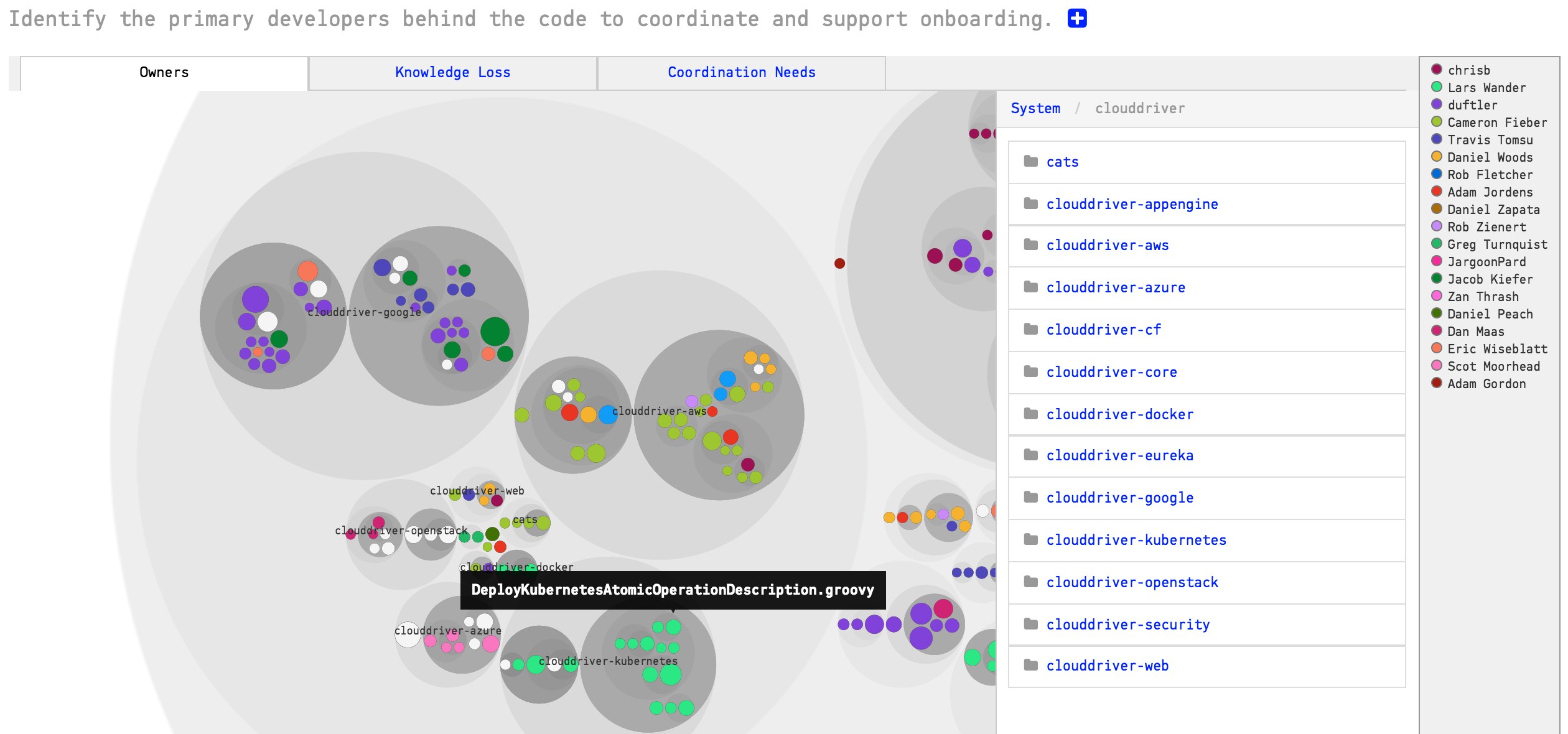
For the purpose of better understanding way more of what we are talking about, we will be diving deeper into this online toolset called Codescene.io, which is free for open source projects.
Needless to say, apart from being a great helper with a nice UI, the platform is mostly based on an open source project called code-maat from the same author.
Let’s see what Codescene is capable of…
Hotspots
In essence, a hotspot is complicated code that you have to work with often.
Its calculation is pretty simple:
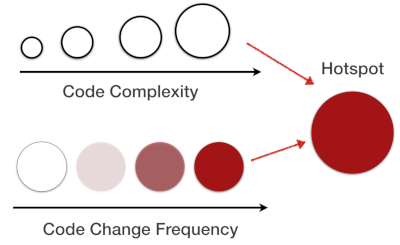
With a Hotspot analysis we can get a hierarchical map that lets us analyze our codebase interactively.
By using one of the examples of the platform, we can check the following visualizations where each file is represented as a circle:
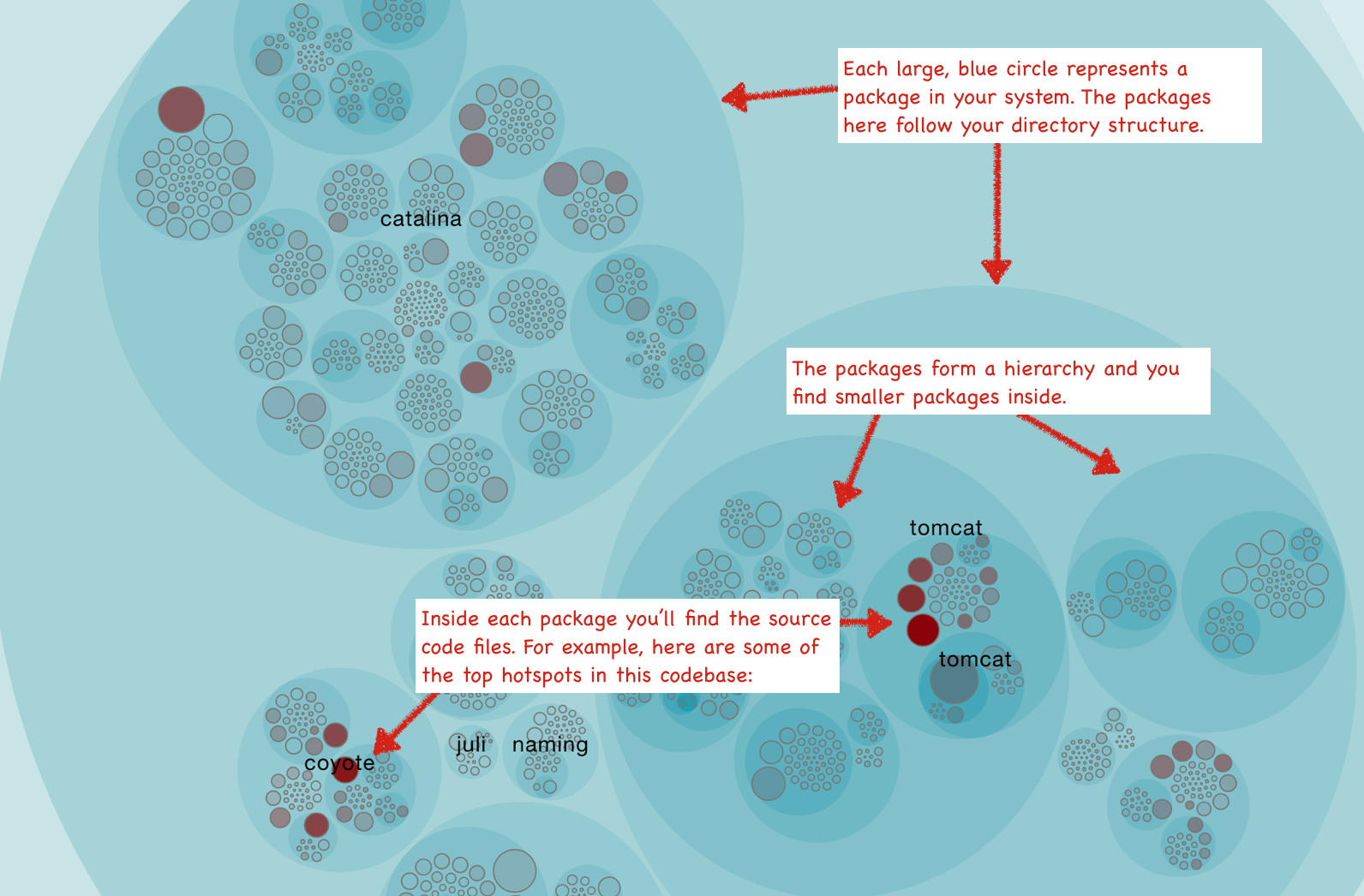
As we can see, we can also identify clusters of Hotspots that indicate problematic sub-systems.
By clicking on a Hotspot we can get more details to get deeper information:
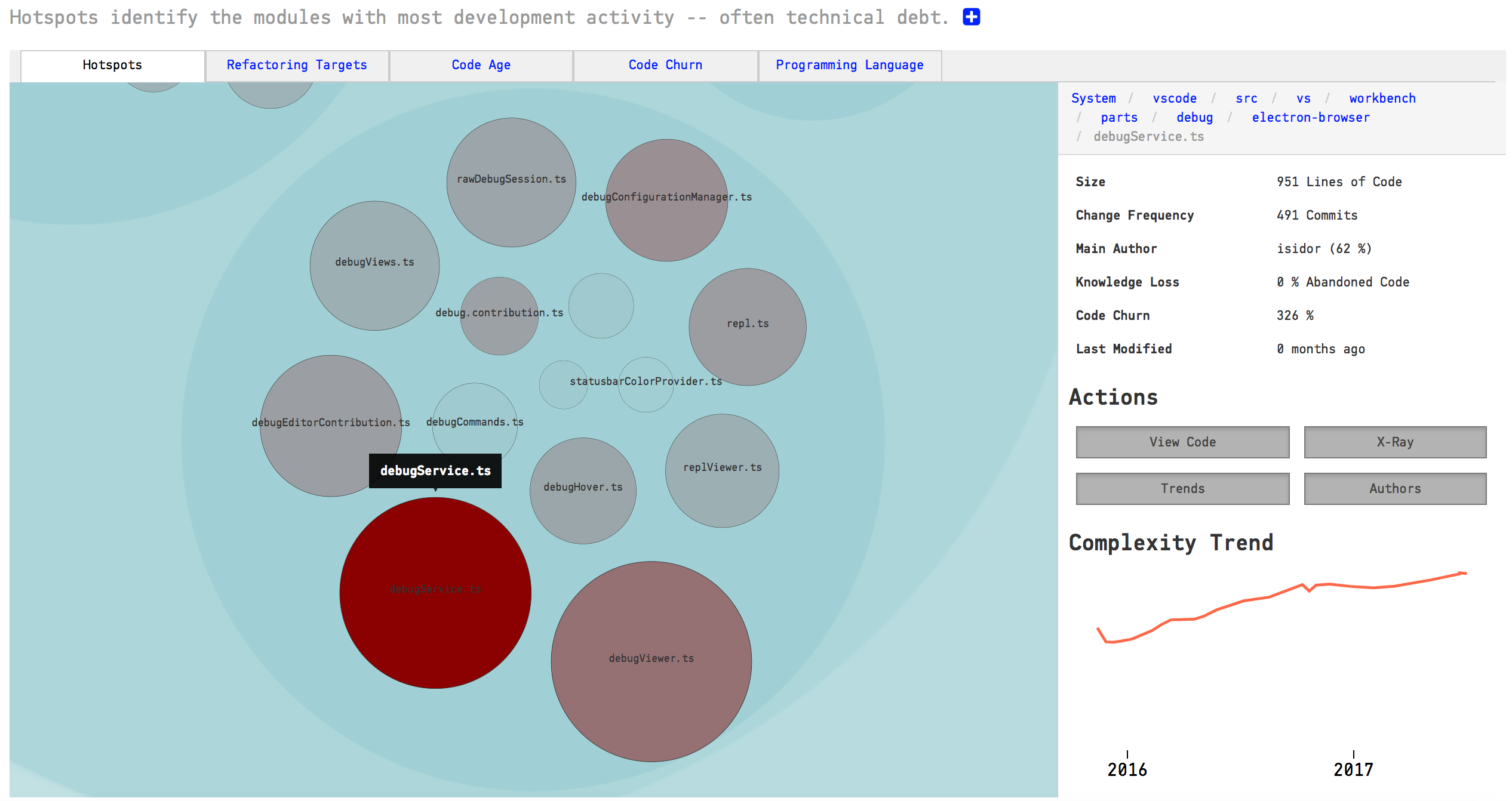
The main benefits of a Hotspot analysis include:
Maintenance problems identification: Information on where sits complicated code that we have to work with often. This is useful to prioritize re-designs.
Risk management: It could be risky to change/extend functionality in a Hotspot for example. We can identify those areas up-front and schedule additional time or allocate extra testing efforts.
Defects Detector: It could identify parts of the codebase that seem unstable with lots of development activity.
Here is the full documentation with more details.
Code Biomarkers
In medicine, biomarkers stand for measurements that might indicate a particular disease or physiological state of an organism. We can do the same for code to get a high-level summary of the state of our hotspots and the direction our code is moving in.
Code biomarkers act like a virtual code reviewer that looks for patterns that might indicate problems.
They are scored from A to E where A is the best and E indicates code with severe potential problems.
Let’s have a look at a couple of examples listing risky areas of our code base:
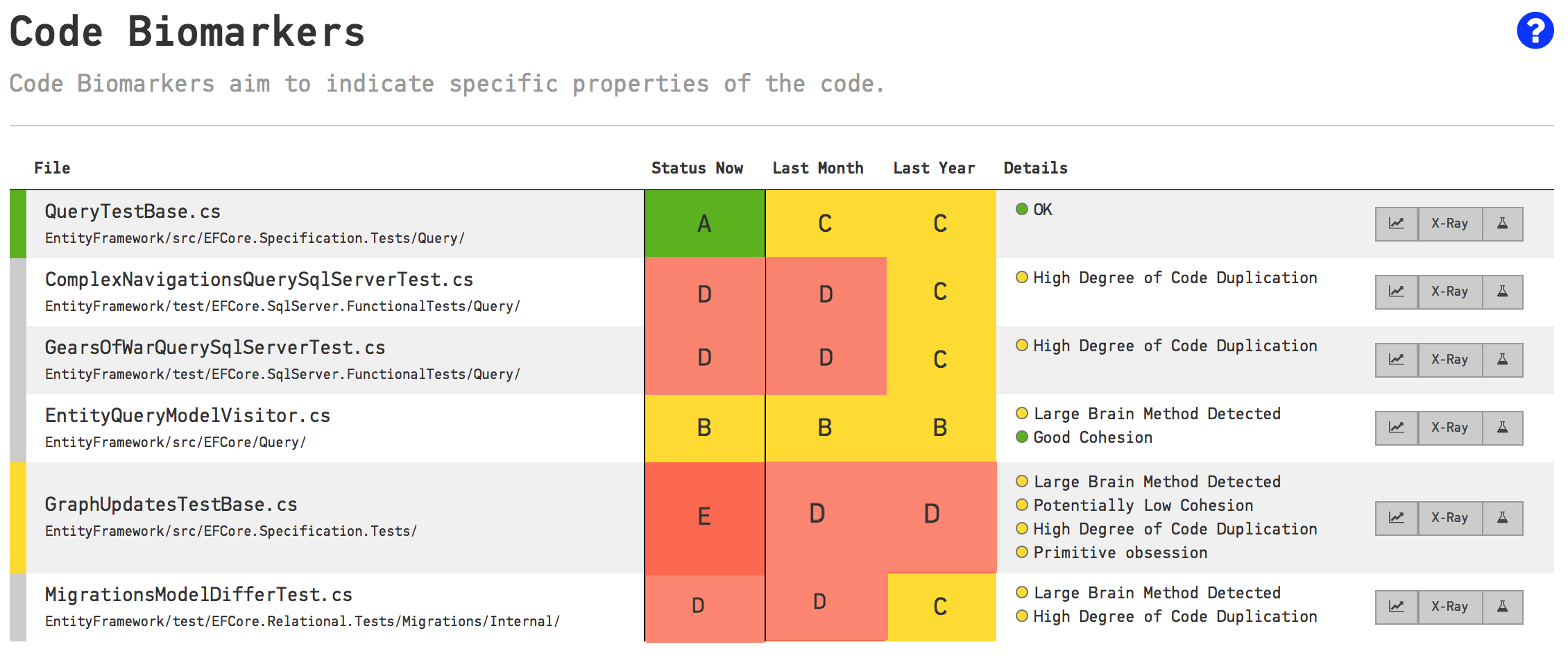
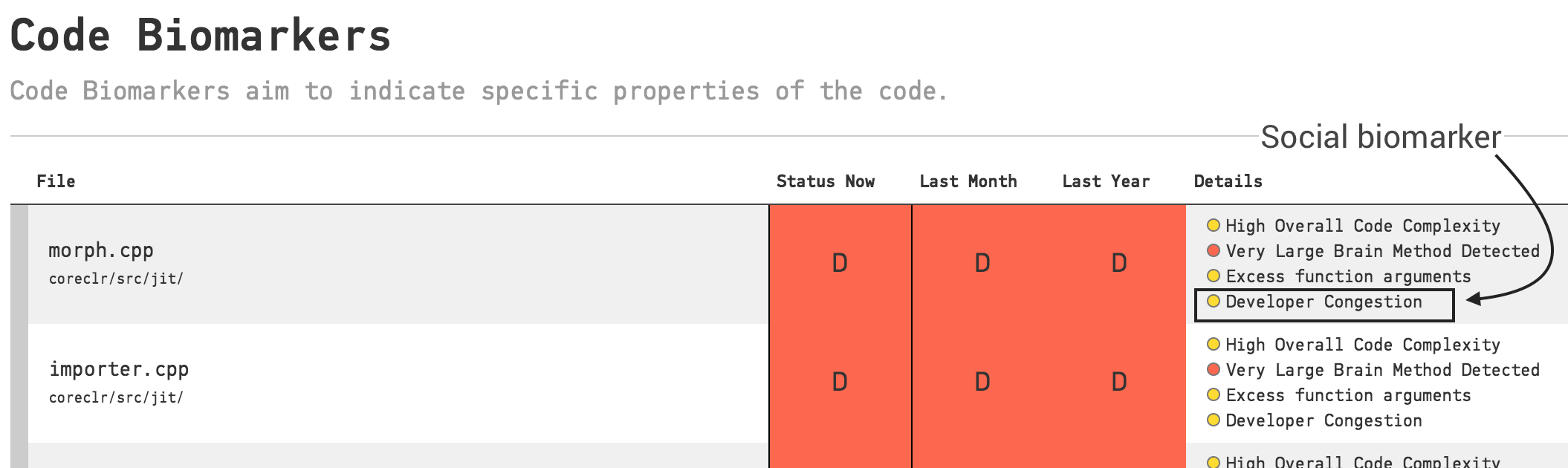
In conclusion we can use Code Biomarkers to:
To decide when it’s time to invest in technical improvements instead of adding new features at a high pace.
Get immediate feedback on improvements.
Same as with hotspots, here is also the biomarkers full documentation.
Covering more Social Analysis
There is way more to cover in this field like:
But from here I will leave it to you, otherwise this article will be too long and, by the way, the idea was to wake up your curiosity (luckily I have achieved it) and shade some light on what is possible by exploring the social side of the code.
“Behavioral code analysis helps you ask the right questions, and points your attention to the aspects of your system – both social and technical – that are most likely to need it. You use this information to find parts of the code that may have to be split and modularized to facilitate parallel development by separate teams, or, find opportunities to introduce a new team into your organization to take on a shared responsibility.”
- Where should we focus improvements?
- Where are the risk areas in the code?
- Any team productivity bottleneck?
I definitely encourage you to give Codescene a try either within an open source repo or within the existent samples, you will be surprised how much curious stuff you find :).
Extra Ball
I would like to introduce an open source repository visualization tool called Gource.
Here is how the author describes it:
“Software projects are displayed by Gource as an animated tree with the root directory of the project at its centre. Directories appear as branches with files as leaves. Developers can be seen working on the tree at the times they contributed to the project.
In essence you can grab your git repository, run gource on it and the result is something like this (This is an example of the Bitcoin repository and its evolution):
The documentation sits at the Gource Github Wiki.
As a trick we have had it in a monitor during sprints to make more visible and transparent how we move around our codebase. Really fun!
Paying Technical Debt
“The best way to reduce technical debt in new projects is to include technical debt in the conversation early on.”
As this quote suggests, this is more at a process level, and even though we have our refactoring toolbox, without the effort of the team, would be impossible to minimize future technical debt and repair existent one.
So let’s see how we can deal with these contexts by pointing out a few tips for the action plan.
- At Team level:
- Prioritize and keep track of technical debt: During the sprint planning for example.
- Allocate time to address technical debt: Also During the sprint planning or when estimating a task that requires touching a sick part of the code.
- Tech Debt Days: Another great practice where the team spends an entire day only focused on repairing affected code.
- At Company level:
- Educate people about its existence: Cost of delay: This metric helps to make visible how much time a team loses due to technical debt.
- Make it transparent: Talk, talk and talk and always bring it up to the table.
- Communicate it properly: An idea would be to add a tech debt update meeting about the current state of it.
As a conclusion, I would like to finish this section with a bunch of quotes from Adam Tornhill (a reference in this field):
“Technical debt can be a frustrating and de-motivating topic for many Development Teams.”
“The keyword is transparency.”
“Explain the cost of low-quality code by using the transparent metaphor of ‘technical debt’.”
“Make technical debt visible in the code using a variety of objective metrics, and frequently re-evaluate these metrics.”
“Finally, make technical debt visible on the Product and/or Sprint Backlog.”
“Don’t hide Technical Debt from the Product Owner and the broader organization.”
Wrapping up
Technical debt is a ticking bomb and as our lovely Batman from 1966 (characterized by Adam West) would say (you can check the full 2 minutes video here, BTW one of my favorite scenes ever):
And based on this inspiring quote let me rephrase it to:
It is a reality that technical debt exists in 99% of the codebases, it is also an important challenge we must face to keep the healthiness and maintenance of our software projects.
Hopefully there is light at the end of the tunnel and with the different techniques mentioned above, now you have a couple of new tools in your toolbox to address it effectively.
Have fun and do not let technical debt beat you.
Congratulations! Technical Debt GURU Level Unlocked!
Part of this article came out of a talk I gave about TECHNICAL DEBT recently, you can check the slides:
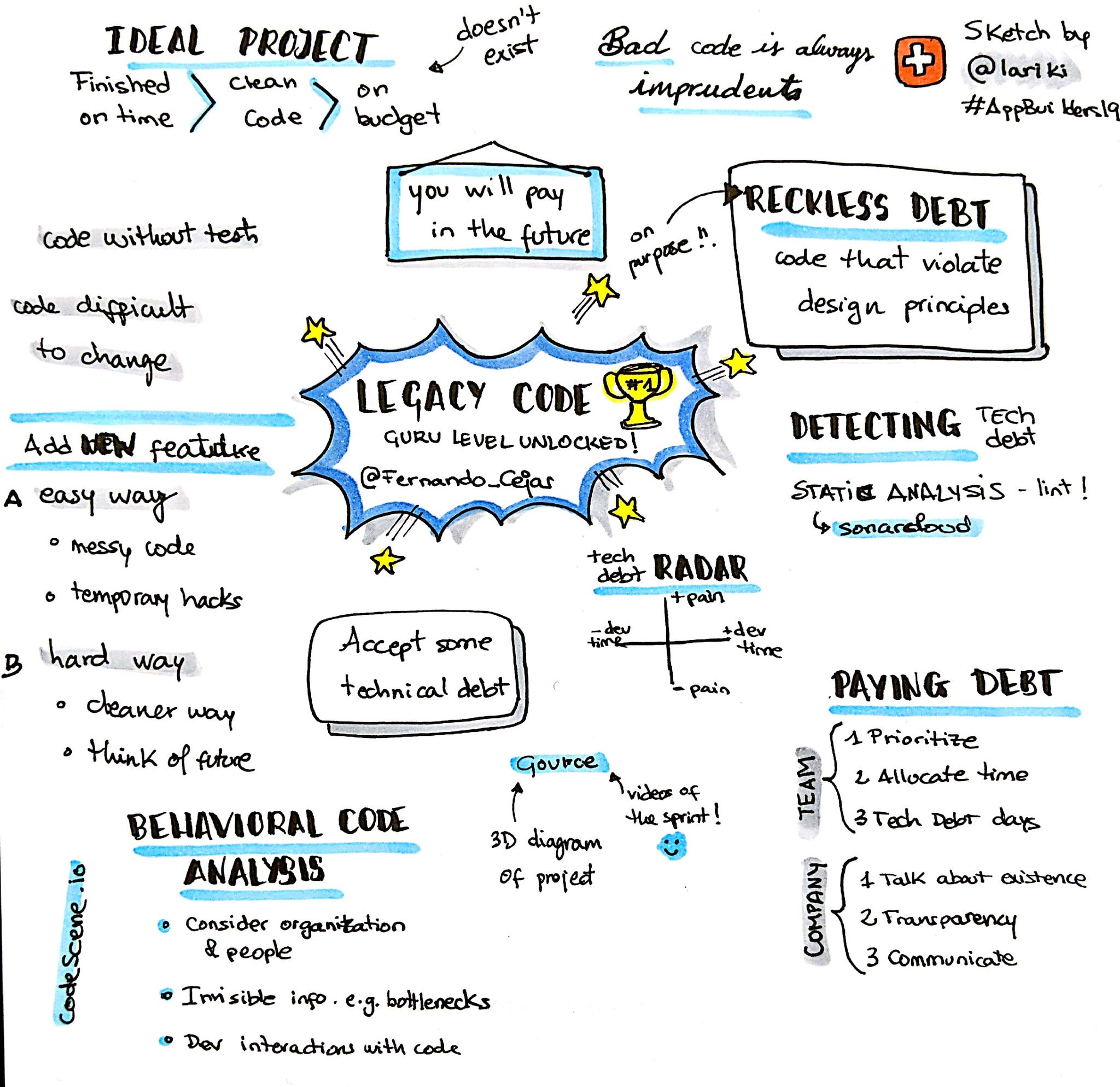
There is also a sketch that perfectly summarizes the main idea of my talk, courtesy of @lariki and @Miqubel:
And finally a video of my talk at Mobiconf:
Books for reference
Further reading
- Technical Debt by Martin Fowler.
- How to deal with Technical Debt in Scrum.
- What Technical Debt is and how to calculate it.
- There are 3 different types of Technical Debt.
- Code Analysis Tools.
- Software Evolution Part 1.
- Software Evolution Part 2.
- Technical Debt explained.
- In defense of Tech Debt.
- How to manage Technical Debt.
- People and Code.